Mapping of RNA Editing Sites Across the Human Genome Opens the Door to Treatments of the Future
RNA editing is a promising new field of research aimed at improving personalized medicine by harnessing one of the oldest and most widely used hereditary mechanisms.
RNA editing is part of the intracellular immune system which enables the production of proteins not included in the original genetic code, thereby further broadening the variety of proteins that can be produced from the genetic code in the DNA.
In the coming years, scientists in the fields of biotechnology and computational biology hope to harness the body's RNA editing capability in order to correct genetic defects and cure serious diseases that are currently incurable, including cancer.
To understand RNA editing mechanisms, scientists first needed to map the regions of the genome where RNA editing occurs.
In the human body, the primary genetic editing protein is an enzyme called ADAR - "adenosine deaminase acting on RNA". Groundbreaking research from Prof. Erez Levanon's laboratory of computational biology in Bar-Ilan University, in collaboration with Prof. Eliyahu Eisenberg from the Tel Aviv University Faculty of Exact Sciences, sought to map the sites in the human genome where ADAR-mediated genetic editing occurs.
Background: DNA, RNA, and proteins
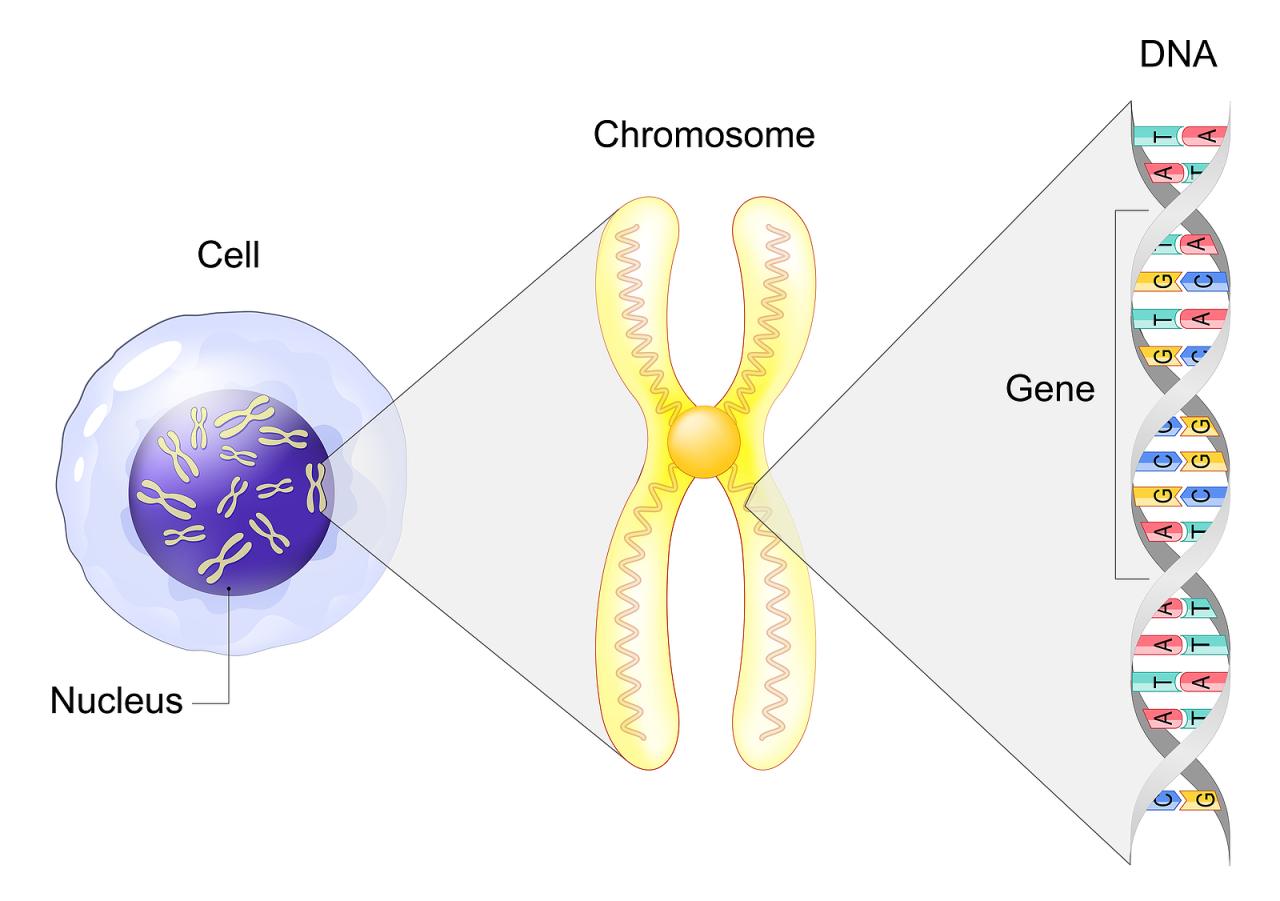
To understand the mapping process the researchers intended to perform, it is necessary to first understand how proteins, which are the body’s building blocks, are produced. The starting point is the hereditary information encoded into the organism.
The sum of an organism’s hereditary information is called a genome and is encoded in the DNA molecule, which is constructed as a chain of nitrogenous bases called nucleotides. Each DNA molecule consists of four nucleotide subunits, which are the four bases of the genetic code: adenine (A), guanine (G), thymine (T), and cytosine (C). These four subunits are paired along the two DNA strands. The human genome consists of an accurate sequence of more than three billion such pairs of bases. 99% of the human genome sequence is identical in all humans, with less than 1% reflecting the genetic variation between people.
 The nucleotide sequences forming the DNA strands
The nucleotide sequences forming the DNA strands
Based on the information encoded in the DNA, cells produce proteins through the following two-stage process:
- Transcription of the genetic information in the DNA into RNA molecules - which are similar but smaller molecules that combine usually into a single strand made up of the same sequence of nucleic acids transcribed from the DNA code. The RNA molecule also consists of four base types: A, C, and G mentioned earlier, and uracil (U) which replaces thymine - T.
- Translation of the RNA code in order to produce proteins -the body's building blocks. This process is done by the Ribosomes – unique structures of RNA and proteins akin to microscopic machines which assemble chains of amino acids into different proteins according to the information coded in RNA sequences called Messenger RNA.
In between these two stages, cells employ control mechanisms affecting nucleic acids and proteins. One of those control mechanisms is a natural RNA editing mechanism.
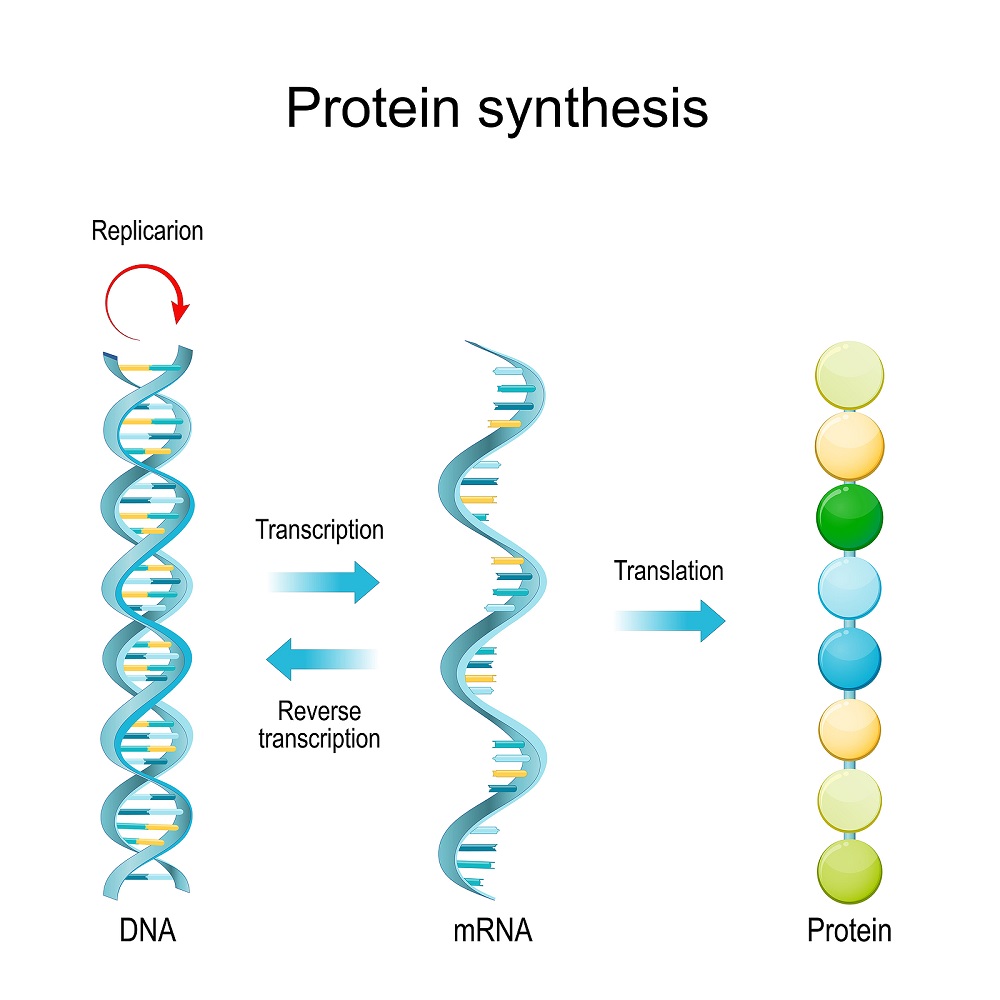 From DNA to RNA to protein: The main transcription and translation stages
From DNA to RNA to protein: The main transcription and translation stages
RNA editing: the body’s natural control mechanism
The natural RNA editing mechanism was first discovered in plants in the 1980s, but has since been observed in almost all multi-cellular organisms. RNA editing plays a role in many biological mechanisms, from the innate immune system to the development of the nervous system.
In the RNA editing process, the nucleotide sequence in the RNA molecule is altered after its transcription from the DNA and before it is translated into a protein. When this editing process occurs in coding genes, it causes the cell to produce additional proteins beyond those included in the DNA sequence. These proteins have a different function than the originals and can be used in different circumstances. In other words, the RNA editing mechanism enriches the biological complexity that can be generated from the genomic sequence. For example, substitution of the C nucleotide with the U nucleotide in intestinal cells leads to the production of the Apo B-48 protein, which helps absorb nutrients from the intestines into the body.
Even in non-coding regions of the genome, RNA editing is essential to the intracellular immune system, since it edits double-stranded regions of RNA and marks them in a way that prevents them from being identified as viruses by the immune system.
In the human body, RNA editing occurs in all cell types, in all body organs, and in huge volumes of millions of edits at any given time. It plays a crucial role in the genetic system itself, in the innate immune system, and in the expression of different proteins.
Studies published in the last decade are beginning to reveal how RNA editing is linked to illness and health. For example, impaired RNA editing has been found to be related to a number of neurological diseases. Impaired RNA editing has also been associated with suicidal depression, schizophrenia, epilepsy, amyotrophic lateral sclerosis (ALS), and even a variety of cancers.
Introducing the research hero – the ADAR enzyme
Genetic editing in different organisms takes place through enzymes. In humans, the primary genetic editing enzyme belongs to the ADAR (Adenosine Deaminase Act on RNA) family and is called adenosine deaminase. Adenosine deaminase is found in the cells of almost all multi-celled organisms.
This enzyme edits the RNA molecule by replacing adenosine (A) with inosine (I). Even though inosine is not one of the five bases mentioned above that make up the DNA and RNA, (A), (C), (G), (T) and (U), the cell’s protein translation system recognizes it as guanine (G) and produces proteins accordingly, as if guanine were in the original code.
Since the adenosine deaminase enzyme naturally knows how to make changes in the RNA code, it may be the future "hero" of RNA-editing-based treatments that correct genetic defects and cure various diseases, including cancer.
The challenges of mapping RNA editing sites
Despite the discovery of an increasing number of RNA editing sites in the body and the mounting evidence as to their significance, so far the attempts to produce a comprehensive map of these sites have failed. The reason for this is that mapping RNA editing sites involves complicated challenges.
The way to map and identify genetic editing sites is to compare RNA sequences to the genome in order to detect discrepancies – for example, finding where A nucleotides have been replaced by G nucleotides. However, not every such discrepancy indicates genetic editing. In fact, in any average sample of sequences it is possible to find multiple discrepancies between the DNA sequence and the RNA sequences that are unrelated to the genetic editing mechanism and are mostly indicative of variations in the population or mere technical errors.
Thus, it became necessary to develop a computational system that could incorporate the multiple steps required to map RNA sequences against the genome, and effectively distinguish discrepancies resulting from genetic editing from discrepancies caused by other factors.
This task involves several challenges. First, scientists need to distinguish genetic editing from variations of the DNA sequence known as SNP (single nucleotide polymorphisms), which may differ from person to person and are not indicative of genetic editing. Second, the genetic sequencing process itself, which involves the conversion of RNA molecules into complementary DNA (cDNA) molecules, can create mutations misinterpreted as RNA editing sites. Third, in order to compare the RNA sequences to the DNA code, the RNA must first be mapped, hence errors in the mapping of RNA to the genome may also lead to the false detection of “discrepancies” that do not exist. On top of that, a large number of edits are known to occur in non-coding regions of the DNA which are highly repetitive, and therefore are difficult to map.
In the present study, which was published in the prestigious scientific journal Nature Communications, the researchers sought to reveal one of the most important and common mechanisms in the genetic transcription process of most living organisms – RNA editing that involves the A base being replaced with the I base by adenosine deaminase (ADAR).
To do this, the researchers developed a new method capable of identifying RNA editing sites and overcoming the above challenges thereby revealing a complete map of 1,517 editing sites.
Study Methods
This computational study was based on analyses of large amounts of human and animal genetic samples and sequences.
The primary source of information used by the researchers was human RNA sequencing data taken from the RNA sequencing samples of the GTEx project, an international research database for the research of gene expression across various body tissues. A total of 9,125 samples of RNA sequences from 47 different tissues from 548 donors were studied.
RNA sequencing data of other mammals was collected from a variety of sources, and a total of 5,673 RNA sequencing samples from 21 non-human mammalian species were studied.
Although the files associating RNA sequences with their "correct" genetic sequence were available to the researchers, they preferred to ignore the previous maps, which could possibly mask the locations of the editing sites. Instead they chose to use raw data to map the hidden editing sites.
Digital mapping of biological information
The researchers converted the sequences into a binary format known as BAM -which is used for storing genetic information, and mapped them in alignment with a reference human genome.
The researchers then analyzed all the discrepancies observed between the DNA code and the RNA sequences by a variety of parameters that allowed them to isolate sites of substantial editing activity, and ignore editing-like instances caused by genetic variations or by other technical reasons.
In short, the researchers focused on coding regions of the genetic sequence, and ignored genetic editing in non-coding DNA regions. They also ignored areas where multiple base substitutions were observed, assuming that these areas resulted from incorrect technical association of genetic code with the RNA sequence.
The researchers then filtered mismatches found in a small number of donors, assuming they represented specific substitutions that reflect individual differences. They also filtered areas where the observed editing rate was less than 1%.
This way, after filtering the results, they were able to obtain an accurate picture of 1,517 coding sites where A-to-I genetic editing occurs. They also showed that these edits occur at the same particular locations across the gene.
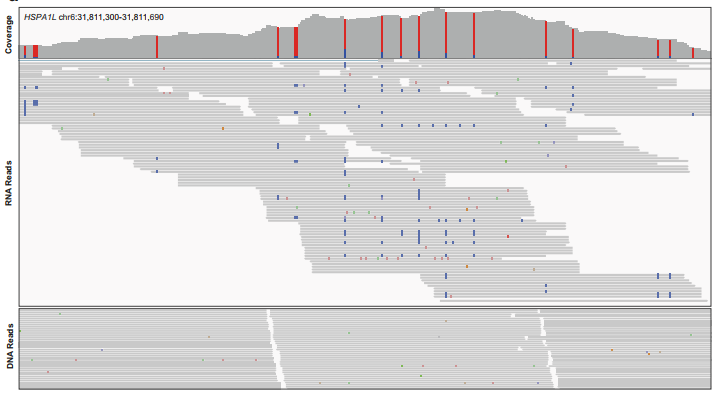 A cluster of editing sites in the HSPA1L gene. 19 RNA editing sites were discovered in this section, which contains 391 base pairs. In the middle: discrepancies between DNA and RNA (red – A-base substitution, blue - G-base substitution). On the bottom: a comparison between the DNA sequence and RNA sequences from three different donors; the editing sites were found at corresponding locations
A cluster of editing sites in the HSPA1L gene. 19 RNA editing sites were discovered in this section, which contains 391 base pairs. In the middle: discrepancies between DNA and RNA (red – A-base substitution, blue - G-base substitution). On the bottom: a comparison between the DNA sequence and RNA sequences from three different donors; the editing sites were found at corresponding locations
Results: a new mapping mechanism
By focusing on genetic editing in coding DNA regions and filtering millions of discrepancies unrelated to these sites, the researchers were able to locate 1,517 A-to-I editing sites in humans, almost all of which had not been known.
In order to demonstrate the accuracy of the computational tool they had developed, the researchers mapped the gene editing sites in 21 other mammals and were able to identify genetic editing sites that had been known in mice.
Based on their findings, the researchers propose a new approach with a detailed mechanism for identifying RNA editing sites in DNA coding regions.
The bottom line
ADAR-mediated mapping of A-to-I RNA editing sites opens the door to additional studies that will unveil the full potential of RNA editing as seen in tissues, biological processes, and diseases. Using these maps, researchers will be able to develop a wide variety of RNA engineering strategies to treat both genetic and acquired diseases- such as cancer.
Potential cure for rare genetic diseases
Technological advances in genetic sequencing and computing have helped computational biology scientists reveal the roles of this mechanism, and they hope that in the coming years they will be able to use it to repair genetic defects that cause serious diseases.
As efficacious as other advanced genetic engineering technologies such as CRISPR, this ADAR-mediated RNA editing approach has real potential to correct genetic defects known to cause incurable hereditary diseases . In addition, unlike DNA editing, which can cause irreversible and sometimes undesirable genetic changes, RNA molecules are transient- they only exist for a short period of time- and therefore their side effects are reversible. Should dangerous or undesirable side effects be detected. the treatment can be discontinued without any long term damage.
Last Updated Date : 15/01/2023